Dominic Gunn





At Turnitin we’re slowly beginning to dip our toes into the world of Kubernetes, I’ve wrote a little about that before but as time has progressed we’ve began to ship more and more software onto our clusters and slowly transition little pieces of traffic over to our new infrastructure.
This experience begins on an otherwise calm and ordinary afternoon but quickly escalated to a completely unexpected and surprise experience that deserved its own blog.
The Incident
We have a variety of clusters at Turnitin serving different regions but all currently backed by infrastructure in AWS and provisioned by kube-aws, as you might expect we also have a large number of alarms to help monitor the health of our clusters.
During the spin up of each of our clusters we had configured the clusters cluster.yaml to setup a private ELB for the cluster API, provided the appropriate subnets, CIDRs and hosted zone and then let kube-aws do it’s thing.
Months passed and nothing was a miss on any of our clusters until this happened
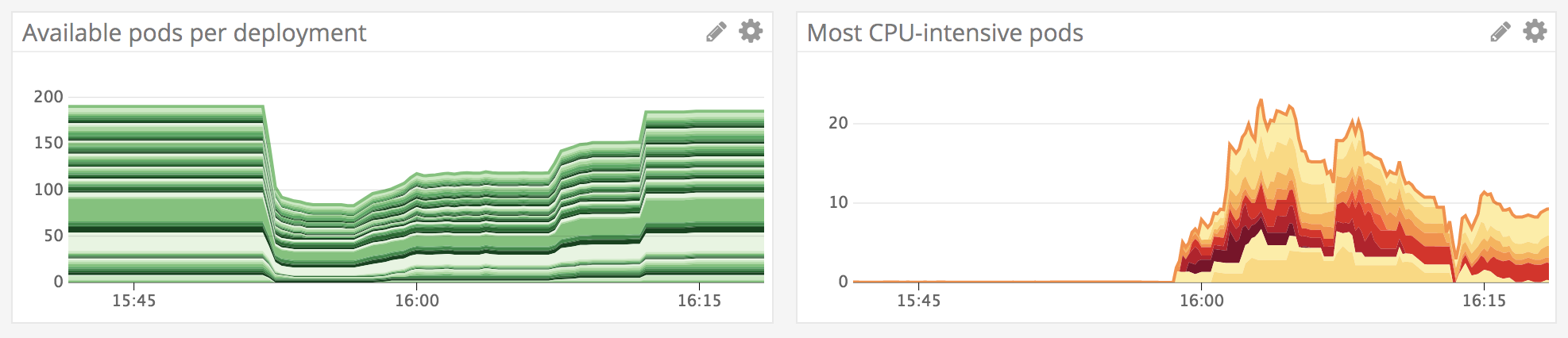
The outage lasted just over 15 minutes, with minor service disruption lingering a little while longer, so what happened? Did one of our operation engineers touch the cluster? Had a deployment gone really wrong? Where had all of our pods gone?
Investigation
Initially we were a little lost, we hadn’t really seen this type of outage occur before so checked the health of our nodes, around half were reporting a NotReady state. Worryingly this was also one of our quieter clusters especially so given the time of the incident, it is responsible for traffic on a continent where users were still sleeping.
Investigating a little showed that Kubelet on those nodes had stopped reporting, I’ve trimmed a little bit of data here to keep things concise.
➜ $ kubectl describe node a-problem-node.internal
.....
Conditions:
Type Status Message
---- ------ -------
OutOfDisk Unknown Kubelet stopped posting node status.
MemoryPressure Unknown Kubelet stopped posting node status.
DiskPressure Unknown Kubelet stopped posting node status.
Ready Unknown Kubelet stopped posting node status.
This was weird, why had around half of our nodes suddenly stopped reporting? During the investigation one of our engineers stumbled upon this log:
streamwatcher.go:109] Unable to decode an event from the watch stream: read tcp 10.69.12.245:50538->10.69.14.11:443: read: no route to host
We checked the health of one of the NotReady nodes and sure enough noticed a huge networking spike, this was not normal behaviour.

Suddenly things started to fall into place, one of the dynamic IPs assigned to the ELB providing access to cluster api had changed, and the change did not propagate through to our Kubelets.
Resolution
We are not the only company to fall foul of this particular issue, infact you can find more indepth discussion regarding it on this Github issue.
Actions to help prevent this occuring again have now began to be put in place, the cause of the outage is one that we had not originally anticipated so had not guarded against but this felt like an experience that we could and should share.
As time goes on, I hope that I have less of these to write about despite that being saddening given how great these experiences are to share.